on
Indian Native Language Identification-(INLI)

|
Shared Task on Indian Native Language Identification-(INLI) |
|
| Task Description :- | Visitor No. |
|
In India, English is the most important language and has a status of the associated language. After Hindi, it is the most commonly spoken language in India and certainly the most read and written language. The number of second language speakers of English has constantly been on the increase and this has also contributed to its rich variation. English is blended with most of the Indian languages and is used as a second language or the third language frequently. Regional and educational differentiation distinguish the language usage and shows the stylistic variations in English. Spoken English shows great variation across the states of India and it is relatively easy to identify the native speaker using their English accent. But finding the native language of the user based on the comments or posts written in English is a challenging task in the current scenario
Native Language Identification (NLI) is the well-known shared task its focus was to identify the native language of non-native speakers, First Native Language Identification task conducted at 2013 based on essays and 2016 spoken responses used to identify the native language globally. Recently announced NLI shared task (co-joined with EMNLP) is proposed to conduct using the essays and spoken responses from the two previous tasks. A well-known workshop PAN included the "language variety identification in Twitter" in their Author Profiling task - 2017 . Here, we have proposed a shared task to identify the native language of an Indian user based on their comments in social media
The task is to identify the native language of the writer from the given Text/XML file which contains a set of Facebook comments in English language.
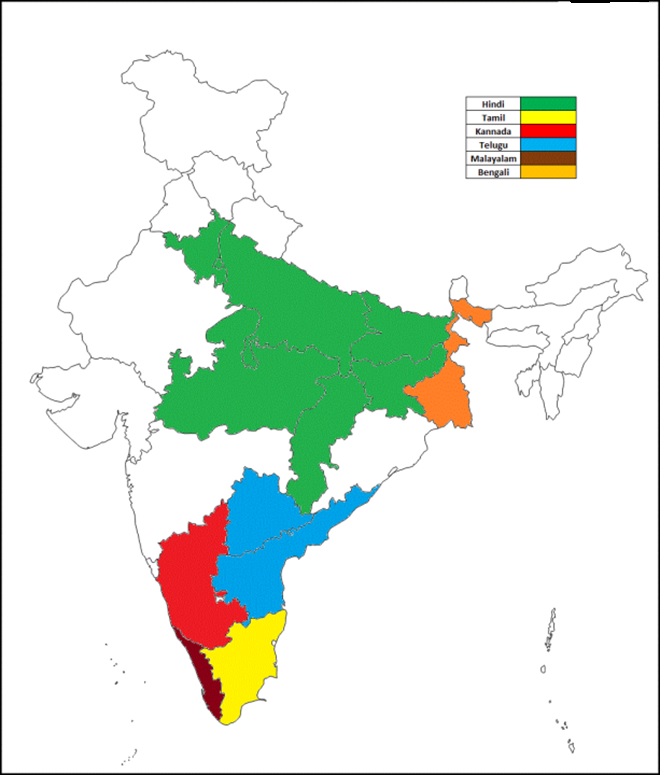
Six Indian languages are proposed to consider for this shared task they are Tamil, Hindi, Kannada, Malayalam, Bengali and Telugu.
Native Language Identification (NLI) can be important for a number of applications. In forensics, native language is often used as an important feature for authorship profiling and identification. Nowadays due to the huge usage of social media sites and online interactions, receiving a violent threat is a common issue faced by commuters. If a comment or post poses any type of threat, then identifying the native language of the person will be one of the significant measures in finding the source.
* Six India languages named as classes TA, MA, HI, BE, TE and KA covering different states of India are considered for this INLI shared task. Languages Covered in India
* We have identified the official Facebook pages of prominent regional language newspapers of the each region and extracted the comments.
* We assume that only native region individuals interested in the regional language newspaper apart from others.
* We have removed the native and Mixed script text from the Facebook posts.
* Especially, we have extracted only the comments related to the general news in all over India (Ex: Noteban, Elections, National politics and Sports),
omitted most of the region specific comments in order to avoid the dataset to be biased by its region.